We are celebrating 15 years — and counting — of stories that are deeply researched and deeply felt, that build a historical record of what the city has been.
We are celebrating 15 years — and counting — of stories that are deeply researched and deeply felt, that build a historical record of what the city has been.
In 2011, the New York Public Library established an official unit for digital experimentation — NYPL Labs. Over the six years that followed, what began as a small research and development outfit for special digital projects grew into a visionary think-and-do tank for making the library’s two centuries of collections digital and usable for the years to come. A hybrid team of technologists, librarians, and designers would start to assemble the building blocks of an urban memory infrastructure. Turning vast collections into usable data, connecting maps, photographs, menus and community memories, NYPL Labs created a series of multilayered projects that point the way to a new information ecosystem. As currents efforts in civic tech and open government promote public access to municipal statistics, systems, and services, so does NYPL Labs’ work provide a new, and deeper, understanding of city streets, buildings, and society, over centuries of change.
NYPL ended the Labs’ run late last year. Here, former director Ben Vershbow sits down with Shannon Mattern, expert on all things library, media, and infrastructure, to debrief on the Labs’ work and the library as a critical urban infrastructure and resource. How do the library and its collections adapt to the age of Google Maps? How do people connect and contribute to the work of memory creation and collection in the city? Who can build and maintain an infrastructure that preserves our memories and prepares, in the age of Instagram, for “the glut of today and tomorrow”? –M.M.
The New York Public Library has a layered material history in the city. It arose on the site of the old Croton Reservoir, a critical infrastructure for the city. Its shelves were initially stocked with the layered, or consolidated, collections of the Astor and Lenox libraries and the Tilden Trust. Over the years, as media have evolved, as the city has evolved, its collection has come to embrace different media forms, to accommodate different populations and encompass different languages. So I’m wondering how your work at the labs extended the New York Public Library’s history of layered or entangled infrastructures.
We were always reminded of these layers just by being in the building. You could actually see the old reservoir’s foundation in our office. Our work at NYPL Labs was focused on digitizing the library’s rare and unique research holdings and developing new modes of access and engagement around them. You could say that, in doing that, we were contributing to another layer of infrastructure. Or connecting the library to the broader internet infrastructure that had arisen around it.
When the library was established, it was built on a reservoir model. It was meant to serve as a comprehensive repository of knowledge. But there is a conceptual shift happening today moving away from libraries as catch-all repositories toward libraries as nodes in a larger network. Each institution has to figure out the unique role it can play in strengthening that network: through technical and financial contributions, community participation, and their particular collecting, preservation, and outreach strategies — the unique work they do as libraries. Working at the New York Public Library (NYPL) made me only more convinced that pre-digital age institutions have a critical role to play in building the modern information ecosystem: because of the unique assets they hold, but also their values and perspective. It’s about taking the long view, and a commitment to the reliability and persistence of information that’s largely absent in the constant digital churn we live in today. We were always thinking about our work within this larger context of evolving infrastructures. That this is a generational, maybe multigenerational, project of migrating knowledge (and values) to a new context, hopefully without losing those roots, and without abandoning the physical, the hard copy.
We could say that, like the Croton Reservoir’s water, the library’s collection is a critical urban resource. Information resources, reference services, information literacy, all the things that a library provides, are just as integral to what makes the city function and what makes strong citizenry.
And the library contains countless resources produced by the city’s inhabitants and administration, about the city, chronicling its evolution across the centuries. These urban media formed the foundation for many of the Labs’ initial projects. To start, could you talk a bit about some of your mapping projects?
The New York Public Library is justifiably celebrated as a repository of civilizational treasures. They have the original papers of great men and women of history, collections that run the gamut of human creativity and achievement. But we ended up gravitating less toward these “heavy-hitter” materials, and more toward documents of everyday life in old New York, often popular ephemeral materials that, if not for the preservation efforts of the library, would never have survived past their era of origin.
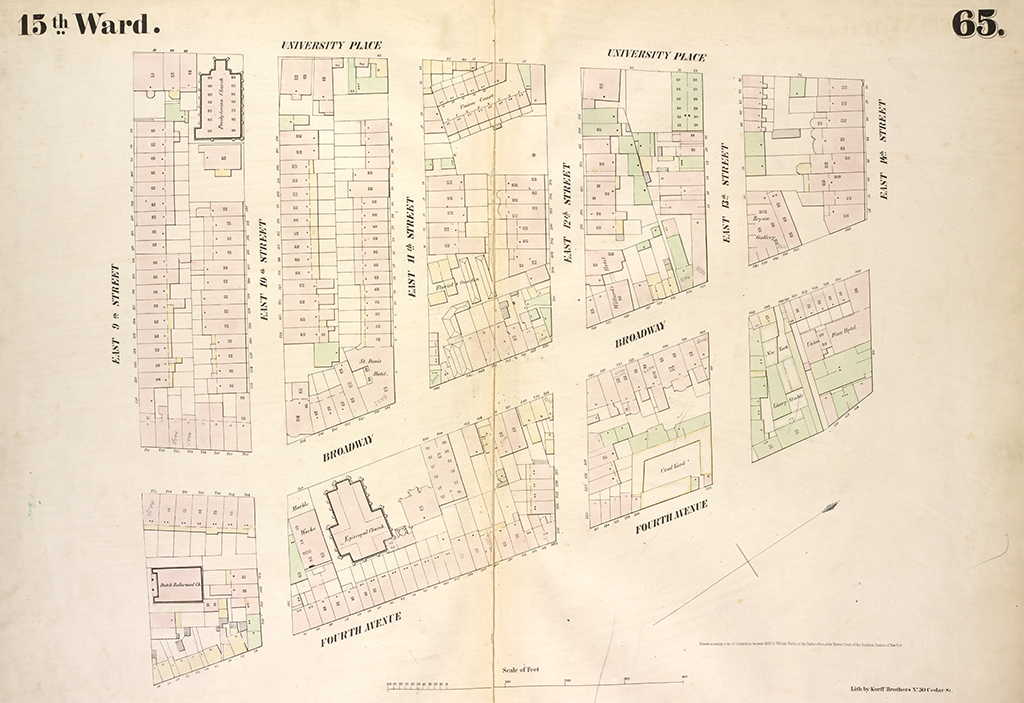
The library’s collections in local history are incredibly deep. It has one of the world’s great map collections, with a high concentration of New York City maps. We became fascinated with a particular subspecies of city maps — fire insurance atlases — which first appeared in the mid-19th century and were produced until well after World War II. They constituted a kind of geospatial information revolution of their time. This was a highly flammable period in New York City history, which had driven the fledgling insurance industry to become more data-driven in its methods, commissioning surveyors to undertake a systematic documentation of the city’s built environment. What were buildings used for (e.g. residential? commercial?)? What sorts of materials were they constructed of? Which industries did they contain? The new maps answered these questions and enabled insurance companies to calculate policies that more accurately reflected a given property’s risk profile.
Little did these underwriters know that they were also performing a kind of cultural insurance: creating an exhaustive record of urban space over the decades. The maps are heavily used to this day by social historians, urban planners, journalists, architectural historians, genealogists, homeowners, environmental researchers. They’re endlessly fascinating to look at because you instantly recognize what they are, and yet they’re describing a city that is no longer here, or that has changed beyond recognition. In the aggregate, they are like the city’s change log. They are a way to travel through time.
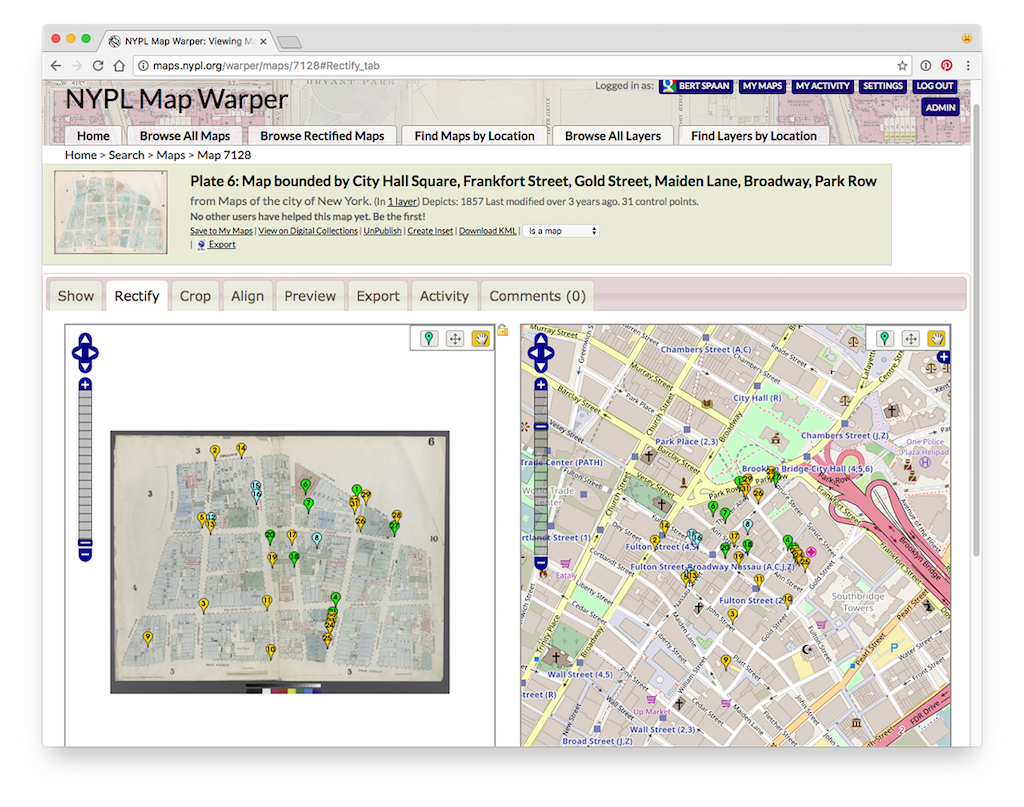
So naturally, the insurance maps became a priority for digitization — to preserve them, but also to work with them in new ways. With some open source mapping folks, the library built a browser-based tool called the Map Warper that allows staff and public volunteers to align historic maps with contemporary maps, a process called “georectification.” You crop out the page borders, stitch the sections together into cohesive tapestries, and what used to be a book of maps becomes an exportable layer of historical geodata that can be analyzed and manipulated with modern cartographic tools like Google Earth or QGIS, or displayed on the web.
Then you turned those digitized maps into quilts of data by demarcating their buildings and streets and making them searchable as data points. Could you talk a bit about the Building Inspector and other projects that allow people to search within the context of individual maps?
If you think of how you use Google Maps today on your phone or computer, you are panning and zooming across a vast canvas. Georectification lets you explore old maps the same way. But the amazing power of a contemporary digital map is that you can ask it questions: where is this address, show me banks in this area, plot a route from A to B. It also gives you context: pictures of the surrounding streetscape, information and reviews of businesses, real-time traffic data, and so on. We thought: What if you could search a historical map in the same way? The library has a wealth of resources referencing places in the past: street photographs, business directories, residential listings, gazetteers (dictionaries of places), newspapers, theater playbills, restaurant menus, the list goes on. If you digitized these sources, then linked them to maps of a corresponding period, you could explore the city’s past in the same way that you navigate its present. The map becomes the library catalog. Of course, to do this you need more than a rectified map, which is still, essentially just a picture. You need hooks to attach all of this other information.
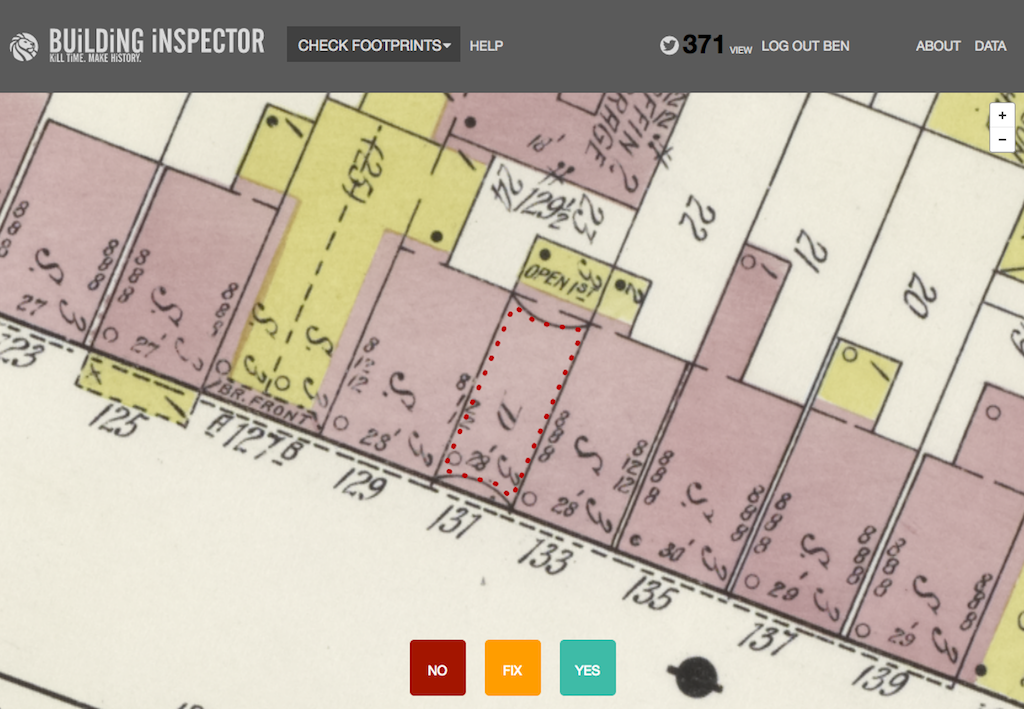
So we began extracting building-level data from the insurance maps — initially tracing by hand, which was an extremely laborious process, but eventually through automated methods. We trained computers to recognize building shapes in the maps, and then invited the public to help out with quality control and deeper indexing tasks. This wasn’t our first foray into “crowdsourcing.” We had had success with this before when we invited the public to help transcribe the library’s remarkable collection of historic restaurant menus. In Building Inspector, we’d ask users: Did the computer identify this building correctly? Or we’d invite them to fix footprint boundaries that the computer had bungled, or identify color codings, transcribe addresses and place names. Over time, through millions of tiny contributions, a dataset emerged describing the city over different time periods which can be used to do new kinds of research.
And people can use the tools you’ve created to do their own scholarship or creative projects?
A great example is work by a couple of professors at Barnard and Columbia. Gergely Baics is an historian, and Leah Meisterlin is an architect and a geospatial information practitioner. The combination of their skills and perspectives around the data sets we released produced some amazing scholarly fireworks. Baics just published a book that relies on this data set, derived (in this case manually, pre-Building Inspector) from an 1854 insurance atlas of Manhattan covering the Bowery to 42nd Street. Having historic building-level data allowed them to analyze land use in the city when market forces operated without regulation, before official zoning laws. They’ve identified emergent patterns in the concentration of residential, industrial, and commercial use, in population density and crowding, in where wealth is concentrated, and in how the rights to land and air and light were distributed inequitably.
You mentioned the possibilities of linking the maps’ data with material from other library collections. The manipulability and portability of these digital materials facilitates cross-referencing that might be more difficult if one were to work with analog materials in the physical library building, where maps and, say, menus are accessible in different rooms. The Labs have also highlighted the potential uses of digitized ephemera, like menus and phone books. What types of urban stories or scholarship has your work on ephemera made possible?
We were drawn to documents of everyday life because of the potential they hold for social history and other kinds of research. They also tend to have tremendous popular appeal. People find them both familiar and strange. Who hasn’t dined at a restaurant or ordered take out? Yet you rarely see a menu from a few decades ago, let alone a century ago. Same with playbills from local theaters. They were disposable materials that were not typically saved, so when you come into contact with them you get a powerful sense of what life was like in another time. These collections have always been heavily consulted in-person at the library by researchers, but when digitized they reach a much larger audience. Encountering them on the web awakens the public to the kind of things a library has.
You’ve also worked a lot with photographs, which allow people to not only tell visual stories but ask historical and critical questions that cross these axes of time and place.
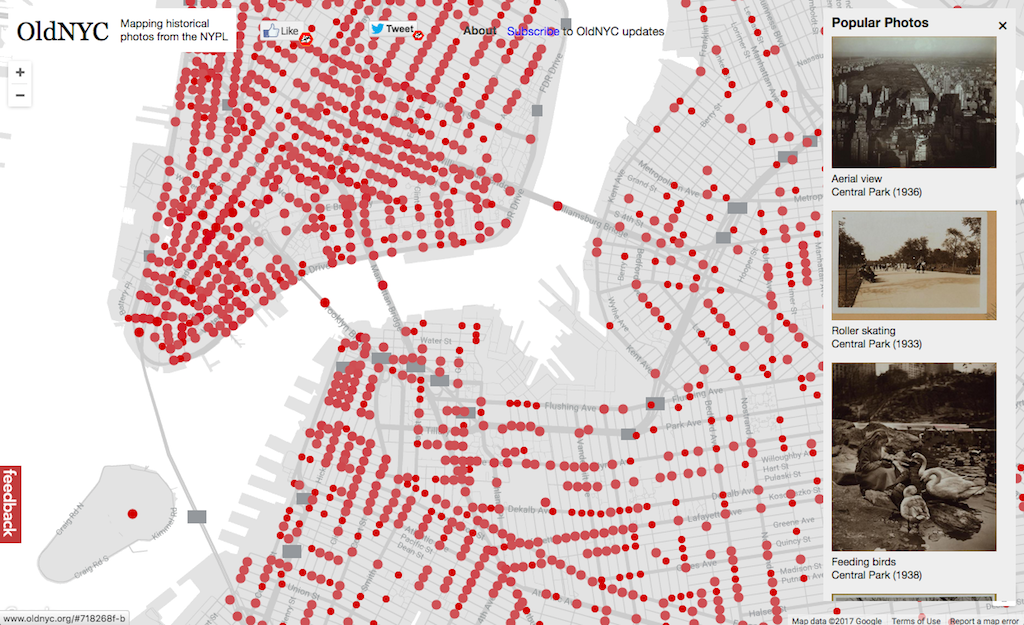
One project that we did involved a large collection of historical street photographs (around 35,000 items) that had been commissioned by the library to document the changing city. Interestingly, this collection had been digitized and released online over a decade ago. But an enterprising developer outside of the library, Dan Vanderkam, had the idea to map them. NYPL Labs and the Map Division helped supply the basic metadata and files, and Dan geocoded the images and built a simple and intuitive website, Old NYC, that allows you to browse NYC’s past on a Google map, bringing up a gallery of photos at each street intersection. With the collection now presented in geographic context, it was as if people were discovering it for the first time. The site has been enormously popular. Another group of volunteers even built a mobile version.
In the grand scheme of things, OldNYC is a prototype for what could be done with NYPL’s urban photography collections (or collections from any library, archive, or museum) at greater scale. If the dimension of time were added, historical maps could also be brought into play, deepening the historical layering. It was also significant in that it was a popular application built outside the library. This is where libraries and museums need to go, transforming into open repositories of data and digital assets that can be interpreted and arranged in ways that the institution doesn’t determine. As with crowdsourcing projects like Building Inspector, we were modeling what this new kind of library — a library built in collaboration with the public — could look and feel like.
In addition to opening up the library to members of the public, some of your projects have also invited the public to insert their own memories and stories into the city’s cultural history. How did your work with oral history bring the library’s publics into its collection?
NYPL is a wonderful hybrid system with great research libraries and the neighborhood branch system in three boroughs, and the Community Oral History Project presented a really exciting opportunity for a crossover: a way of creating a new collection documenting everyday life in New York City but collected through the branch system. The idea came out of the adult education department in the library — actually by a former student of yours, Alex Kelly! — and was facilitated by the adult education staff and the branch librarians. The idea was that the branch libraries could serve as depositories for community memory. Interviews were conducted by local volunteers, and they would help solicit subjects to be interviewed. Sometimes they would switch roles and be interviewed themselves. The model was enormously effective and they started rolling it out all over the city. This was the first time that Labs was involved in the creation of a new collection. We also built some tools to deal with the particular challenges of digital audio, which is difficult to search and discover. We did a lot of work with computer-generated transcripts and, as with Building Inspector, invited the public to help edit and clean them up so they could become fully assessable and discoverable.
And, of course, those stories contain potentially millions of linkages to places, events, people, which can be mapped and associated. So they again present a new corpus of material that can be interconnected with other resources in the library.
How does your work provide an alternative space for technological development, in relation not only to the commercial tech world and start-up culture, but also to civic tech or open government work? Where does the work in a library lab fit into that larger landscape, where not all the players prioritize creating access for, or validating the knowledges of, marginalized communities?
Libraries fill a need for historic preservation, a memory function. And I think that a community without access to its history is sort of living in a state of amnesia. With all of this very turbulent, often inequitable, urban change taking place, having access to history is incredibly important. Whether people are able to meaningfully access that or leverage that involves issues of literacy and access and empowerment, but preserving the historical record and making it accessible is vital for enabling informed approaches to the present and the future. That’s a basic value statement about the importance of libraries and archives, historical societies, and community and grassroots archives, even the person on the block who acts as the informal chronicler of the neighborhood.
The question now is how to create a more participatory model for the preservation and stewardship of cultural memory. The internet has given us things like Wikipedia, which is a remarkable achievement of collaborative peer production. How can those models of networked collaboration be applied at a local level, say, at urban scale? The New York City tree census, which once per decade catalogs every tree on every block of the city, was taken this last time around by thousands of volunteers using open source tools. How do we do the equivalent for neighborhood history on the building and block level? The Queens Library has done amazing work with their community to actually get folks to bring their historical mementos and photographs to the library to be cataloged and curated into the collection. The NYPL oral history project was in some ways taking a page from their book, tapping into the broader community as a source. That kind of collective stewardship could be ennobling and empowering for the community, and is also a practical strategy for dealing with being under-resourced and under-valued. The amount of money that gets pumped into highly speculative, often dubious startups dwarfs library budgets. But by reorienting into a posture of collaboration with their users, heritage institutions can punch above their weight.
And there is absolutely common cause with the civic tech community. Anyone working to open up government information and putting it to work for the public benefit should see libraries as their allies and partners. And of course, as illustrated by the insurance maps, libraries and municipal archives possess the historical antecedents to many of the government data sets that civic hackers are currently working to unleash. So we should be looking at how we can create a single data ecosystem that unites these efforts and resources.
Those visions of progress could be greatly enhanced not only by libraries’ historical perspective and their commitment to preservation, but also by the different values that libraries bring to technical work. There’s a lot to be gained by linking up these different communities.
The question then becomes: Who can really do that work? I think the urban memory infrastructure we need transcends one institution or even sector. Theoretically, one institution could take a leading role building out the network. That was the intention behind our NYC Space/Time Directory project. In more immediate terms, it was about taking our work with historical maps to the next level: creating a framework where the maps and other data-rich New York collections could intermingle in a common format, and on top of which new services could be developed. But the broader vision was to create a framework for the entire city, and one that other cities could use and adapt around their resources. Now that the New York Public Library is shifting away from these kinds of explorations and experiments, the question is: Where does that go, and how does that larger framework get built?
It’s a challenge in addressing so many urban problems: how do you learn from the wisdom of a well-defined locality, and when do you expect that insight to scale? When does scaling up ultimately rip apart the bonds that make something work well in its specific context?
The risk of what I’m proposing is that it becomes this very generic, impersonal platform. It’s got to be done in a way that allows local difference to flourish, but where there’s enough common tooling and standards so that the resources can all mix together and cross-reference. I’m interested in finding a way to create that kind of cooperative framework. I think we took a really good stab at it in modeling some of the possibilities for digital collections at NYPL. Why should those be confined to one institution? Honestly, if we expect users to consult each individual library and museum website when searching for historical resources, we’re kidding ourselves. Discovery happens at the level of search engines, or via Wikipedia. So memory institutions, despite their very real brick-and-mortar boundaries, their distinctive missions, boards, users, and stakeholder communities, need to operate at the network level — by exposing their data and collections so they can be incorporated into the broadest discovery tiers of the web, but also, I would advocate, building some unified local interfaces and services for the communities they directly serve. But we’ll need to work in new ways. The richness of the cultural institutions in New York City is perhaps matched only by their inability to meaningfully collaborate at web-scale.
Returning to our initial metaphor, our urban memory infrastructures have a new, confounding layer to contend with: those most ephemeral of ephemera – social media. What challenges or potentials do these new media forms present to libraries and other cultural memory institutions?
That’s a great question. Social media will undoubtedly become social history, provided we can find a way to preserve and organize it for future access.
We hosted a project at NYPL called “On Broadway,” which was created by Lev Manovich, a pioneering digital scholar at CUNY, working with a talented crew of programmers and designers. It was a large touchscreen interface that allowed you to digitally “stroll” up the artery of Broadway in Manhattan through a curated set of contemporary data streams including Google Street View imagery, median household income, taxi pickups and drop-offs, Foursquare check-ins, tweets, and Instagram photos. Broadway passes through the whole panorama of social worlds in New York City, so it creates a fascinating geo-located portrait of the city via its data.
Placing this installation at the library, and in an exhibition looking at the entire sweep of the history of photography, was a very important provocation. We were asking: Why should this be considered any different? Throughout the 20th century, NYPL was a voracious collector of everyday documents that are now some of our strongest links to the past. Does that activity now cease simply because the documents are in a different format? The scale of things potentially to be remembered is now so enormous that we need to develop new cross-institutional infrastructures that can handle the glut of today and tomorrow. There are inspiring digital preservation efforts like the Internet Archive which show us the way forward. But libraries, archives, museums, universities, nonprofits, and governments need to also step up, especially to look after the local.
Of course we can’t save everything. As has always been the case, we also have to get comfortable with (even embrace) a certain amount of forgetting.
The views expressed here are those of the authors only and do not reflect the position of The Architectural League of New York.